Ever felt like you’re shouting “Stay out!” while waving your arms frantically at a bunch of robots trying to barge into your website’s private rooms? If you’re managing a website or responsible for its SEO, you might have run into this feeling.
Maybe you have some secret pages you don’t want search engines to find, or perhaps you want more control over how your site’s content shows up in search results. This is where the mysterious “X-Robots-Tag” comes into play. But what is it, exactly?
In this article, we’re going to demystify the X-Robots-Tag and show you how it can be your secret weapon for directing those pesky search engine bots. Whether you’re a seasoned SEO pro, a website owner who wants to take charge of your content, or just curious about how the internet works, we’ve got you covered.
What is an X-Robots-Tag?
Think of the X-Robots-Tag like a secret code you whisper to search engine robots as they crawl through your website. It’s a snippet of code you add to the HTTP header of a web page or file. This code gives direct instructions to search engines about how they should handle that specific piece of content.
How Does It Work?
Here’s where it gets a bit technical, but don’t worry, we’ll keep it simple:
- HTTP Headers: Every time you visit a website, your browser sends a request to the site’s server. The server responds with the web page’s content, but it also sends along some extra information called HTTP headers. These headers aren’t usually visible to you, but they play a big role behind the scenes.
- X-Robots-Tag Placement: You insert the X-Robots-Tag into these HTTP headers. It looks something like this:
X-Robots-Tag: noindex, nofollow - Instructions for Search Engines: Each part of the tag gives a specific instruction:
- noindex: Tells search engines not to add the page to their index (the giant library of web pages they use for search results).
- nofollow: Tells search engines not to follow any links on that page.
- Other directives: There are other directives you can use, which we’ll explore later.
Who Needs X-Robots-Tags?
- Website owners with “secret” content: If you have pages you don’t want the public to stumble upon, X-Robots-Tags can help keep them hidden.
- SEOs: Search Engine Optimization pros use X-Robots-Tags to fine-tune how their websites appear in search results.
- Anyone with PDF files or images: X-Robots-Tags aren’t just for web pages – you can use them to control how search engines treat other types of files too.
X-Robots-Tag and SEO
You might be wondering, “What does this X-Robots-Tag business have to do with SEO?” Turns out, quite a lot! Smartly using X-Robots-Tags can actually boost your website’s performance in search results. Here’s how:
1. Controlling Your Crawl Budget:
- What it is: Search engines have a limited amount of time and resources they can spend crawling your website. This is your “crawl budget.”
- How X-Robots-Tags help: By using the
noindexdirective on pages that aren’t important for search (like internal admin pages), you free up your crawl budget so search engine bots can focus on the pages that do matter for your SEO.
2. Preventing Duplicate Content Issues:
- What it is: If you have multiple pages with similar content, search engines might not know which one to show in search results, potentially hurting your rankings.
- How X-Robots-Tags help: You can use
noindexon duplicate pages (like printer-friendly versions or slightly different product pages) to avoid confusing search engines.
3. Managing Index Bloat:
- What it is: If your site has a lot of low-quality or irrelevant pages in the search index, it can negatively impact your overall SEO performance.
- How X-Robots-Tags help: By strategically using
noindexon those low-value pages, you can keep your index clean and focused on high-quality content.
4. Temporarily Removing Pages:
- What it is: Sometimes, you might need to temporarily remove a page from search results (e.g., while updating it).
- How X-Robots-Tags help: The
unavailable_afterdirective lets you set an expiration date for a page, after which it won’t appear in search results.
Alternative Uses for X-Robots-Tags: Beyond Search Engines
While X-Robots-Tags are primarily known for their search engine wrangling abilities, they have a few other tricks up their sleeve:
1. Controlling Other Bots:
- Search engines aren’t the only bots crawling the web. You might encounter bots used for archiving, data mining, or even malicious purposes.
- X-Robots-Tags can be used to give instructions to these other bots as well, helping you manage how your website’s content is accessed and used.
2. Restricting Access to File Types:
- Let’s say you have a folder full of confidential PDFs or images that you don’t want just anyone downloading.
- By setting an X-Robots-Tag with the noindex directive in the HTTP header for that folder, you can prevent search engines from indexing those files.
3. Protecting Media Files:
- Worried about your images or videos being used without your permission?
- The noimageindex directive can prevent search engines from indexing your images, making it harder for others to find and use them without your consent.
4. Managing Email Crawlers:
- Some email clients have bots that crawl web pages to generate link previews.
- You can use X-Robots-Tags to control what information these bots display, ensuring your emails look the way you want them to.
5. Custom Directives:
- While the standard directives cover most use cases, some search engines and bots might support additional, custom directives.
- This can allow for even finer control over how your content is handled, but be sure to research the specific bot you’re targeting to see which directives are available.
Remember, the X-Robots-Tag is a versatile tool. By understanding its full potential, you can go beyond search engine optimization and take control of how your content is accessed and used across the web.
X-Robots-Tag Directives: Your Control Panel
Now, let’s explore the different buttons and levers you can use to give search engines specific marching orders:
- noindex: Tells search engines, “Don’t add this page to your index!” This is great for hiding pages like internal company documents or unfinished work.
- nofollow: Tells search engines, “Don’t follow any links on this page.” Useful if you have links to sites you don’t want to endorse or pass authority to.
- none: This is like a combo deal – it’s the same as using both
noindexandnofollow. - noarchive: Says, “Don’t show a cached version of this page in search results.”
- nosnippet: Prevents a text snippet or video preview from showing up in search results.
- notranslate: Tells Google Translate not to offer a translation of the page.
- noimageindex: Prevents Google from indexing images on the page.
- unavailable_after: Lets you set a date after which the page shouldn’t be available in search results.
- indexifembedded: (Google specific) Allows a page with a
noindextag to be indexed if it’s embedded through an iframe or a similar HTML tag on another page. - nositenavigation: (Bing specific) Tells Bing not to include the page in the site’s navigation bar in its search results.
By incorporating these additional directives, you’ll have a complete picture of the available options for controlling how search engines interact with your content.
Combining Directives
You can mix and match these directives to get the behavior you want. For example:
X-Robots-Tag: noindex, nofollow, noarchive
This tells search engines not to index the page, not to follow links, and not to show a cached version.
Real-World Scenarios
Let’s see how some folks might use X-Robots-Tags:
- The Online Store Owner: Sarah wants to hide her “Thank You” page after a purchase, so she uses
noindex. - The News Publisher: Mike wants to temporarily remove an article from search results after it’s been updated, so he uses
unavailable_after. - The Photographer: Emily wants to prevent her images from being used without permission, so she uses
noimageindex.
X-Robots-Tag vs. Robots.txt: What’s the Difference?
Both X-Robots-Tags and robots.txt files are ways to communicate with search engine bots, but they have distinct roles and capabilities:
| Feature | X-Robots-Tag | robots.txt |
|---|---|---|
| Placement | In the HTTP header of a specific page/file | Separate text file in the root directory |
| Scope | Individual pages or files | Entire website or specific directories |
| Primary Function | Control indexing and other search behaviors | Control crawling (which pages bots visit) |
| Directives | noindex, nofollow, noarchive, etc. | Disallow, Allow, Crawl-delay, etc. |
In a Nutshell:
- X-Robots-Tag: More granular control over individual pages or file types. Focuses on what search engines do with your content (index, follow, archive).
- robots.txt: Broader instructions for which parts of your site search engines should visit.
Which One Should You Use?
- If you want to hide specific pages or files from search results: Use X-Robots-Tags (
noindex). - If you want to prevent search engines from wasting resources on certain parts of your site: Use
robots.txt(Disallow). - If you want fine-grained control over how search engines display your content (snippets, archives): Use X-Robots-Tags.
Can You Use Both?
Absolutely! They can work together. For example:
- Use
robots.txtto tell bots not to crawl your website’s admin area. - Use X-Robots-Tags to make sure specific files (like PDFs) aren’t indexed.
Important Note: If you block access to a page using robots.txt, search engines won’t be able to see the X-Robots-Tag on that page, rendering it ineffective. So, choose your tools wisely!
How to Check Your X-Robots-Tags (Is It Working?)
So, you’ve set up your X-Robots-Tags, but how do you know if they’re actually working? Here are a few ways to check:
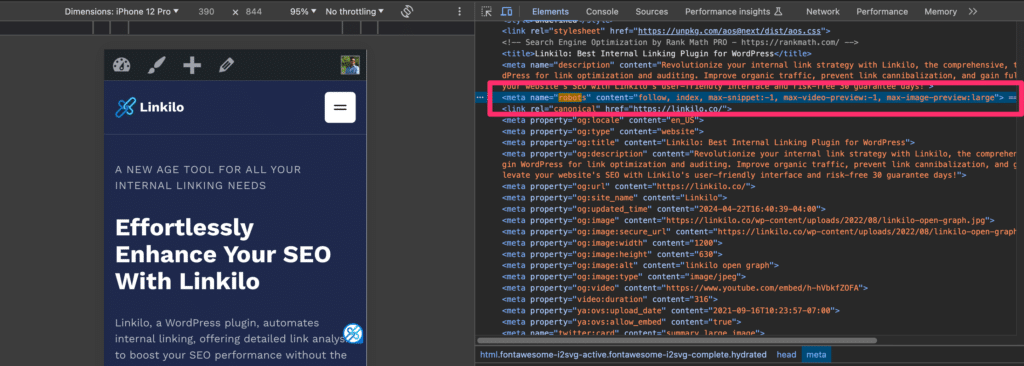
- View Page Source (Basic):
- Right-click on the web page and select “View Page Source” or “Inspect.”
- Look for a line that starts with
<meta name="robots". If you see the directives you set (e.g., “noindex, nofollow”), that means your meta robots tag is in place. - To check HTTP headers, you’ll need to go to the “Network” tab in your browser’s developer tools. Look for the
X-Robots-Tagline in the response headers.
- Online Tools (Easy):
- Several free online tools can quickly check your X-Robots-Tags for you. Some popular options include:
- X-Robots-Tag Checker: This tool allows you to enter a URL and see if the page has an X-Robots-Tag and what directives it includes.
- SEO Site Checkup: This tool checks for various SEO elements, including the presence of a meta robots tag or X-Robots-Tag.
- Browser Extensions: If you use Chrome or Firefox, you can install extensions like Ahrefs’ SEO Toolbar or the Web Developer Toolbar, which make it easier to view HTTP headers and meta tags.
- Several free online tools can quickly check your X-Robots-Tags for you. Some popular options include:
- Google Search Console (SEO Focused):
- If you have Google Search Console set up for your website, you can use the URL Inspection tool to check if Googlebot can see and interpret your X-Robots-Tag correctly.
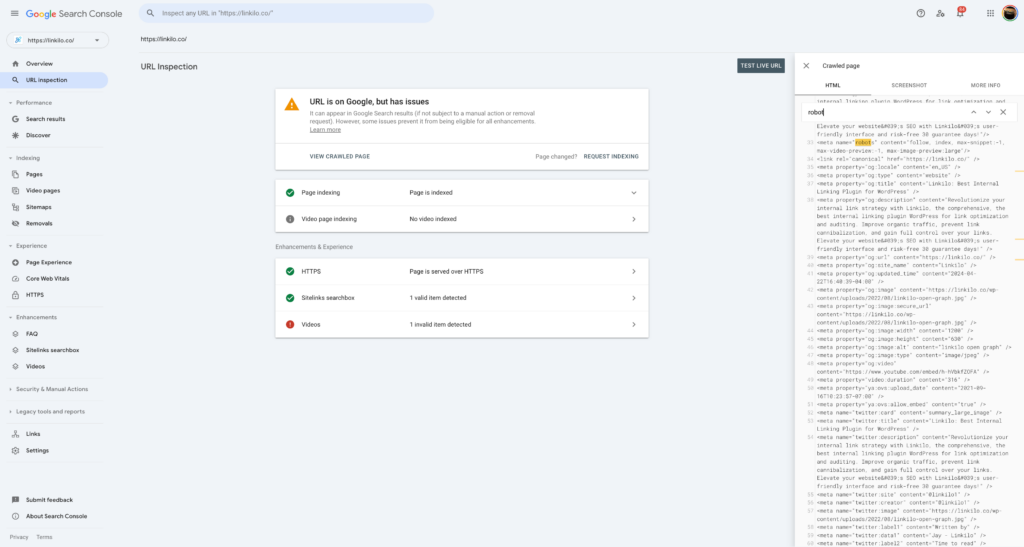
Important Note: Even if your X-Robots-Tags are set up correctly, it might take some time for search engines to update their index. Be patient, and don’t panic if you don’t see immediate changes in search results.
How to Put X-Robots-Tags into Action
Ready to start giving orders to those search engine bots? Here’s how to implement X-Robots-Tags, depending on your website’s setup and your level of technical comfort:
1. Using Meta Robots Tags (Easiest):
- Ideal for: Website owners using WordPress, Wix, Squarespace, or similar platforms.
- How-to:
- Install an SEO Plugin: If you haven’t already, install a reputable SEO plugin like Yoast SEO (for WordPress) or a similar tool for your platform.
- Navigate to Page/Post Settings: Open the page or post you want to edit. Look for an SEO section or tab (usually below the main content editor).
- Find the Robots Meta Tag Field: Most SEO plugins have a designated field for “Meta Robots” or “Advanced Robots Settings.”
- Add Your Directives: Select the directives you want from the options provided (e.g., noindex, nofollow). Some plugins may even allow you to enter custom directives.
- Save and Publish: Save your changes and publish the page. The meta robots tag will be added to the HTML of your page, instructing search engines accordingly.
2. Adding X-Robots-Tag Directly to HTTP Header (Advanced):
- Ideal for: Websites with custom server configurations or where you need more control over specific file types (e.g., PDFs).
- How-to:
- Access Server Configuration: You’ll need to edit the configuration files for your web server (e.g.,
.htaccessfor Apache, configuration file for Nginx). - Add the Header: Insert the
X-Robots-Tagline into the appropriate section of your configuration file. The exact placement and syntax may vary depending on your server. - Restart Server: Save the changes and restart your web server for them to take effect.
- Access Server Configuration: You’ll need to edit the configuration files for your web server (e.g.,
Example (Apache .htaccess):
<FilesMatch "\.(pdf|doc)$">
Header set X-Robots-Tag "noindex, nofollow"
</FilesMatch>This would add a noindex, nofollow directive to all PDF and DOC files on your site.
3. Robots.txt (Limited):
- Ideal for: Simple directives like
noindexornofollowthat apply to an entire website or directory. - How-to:
- Create or Edit robots.txt: This file should be located in the root directory of your website. If you don’t have one, create a plain text file named “robots.txt.”
- Add X-Robots-Tag: Add lines like this to your
robots.txtfile:
User-agent: *
<field>
Disallow: /private-area/Important Considerations:
- Test Thoroughly: Always test your implementation to make sure it’s working correctly before applying it to your live site.
- Consult Documentation: Refer to the documentation for your web server, CMS, or SEO plugin for specific instructions and best practices.
- Seek Help: If you’re not comfortable with editing server files or complex configurations, don’t hesitate to ask for help from a developer or SEO expert.
tunesharemore_vert
Which Method is Right for You?
- HTTP Headers: This gives you the most control and flexibility, but it’s the most technical option. Best for experienced webmasters or those with developer help.
- Meta Robots Tag: The simplest and most accessible method for most website owners. Many CMS platforms offer built-in or plugin-based solutions.
- Robots.txt: A good option for simple directives like
noindexornofollow, but less reliable for more complex instructions.
Important Note: Always double-check your implementation to make sure it’s working correctly! Incorrectly used X-Robots-Tags can have unintended consequences, like hiding pages you actually want indexed.
Advanced X-Robots-Tag Techniques with Regex
If you’re comfortable with regular expressions (regex), you can take your X-Robots-Tag game to the next level. Regex allows you to create more complex and flexible rules for controlling how search engines handle your content.
Here’s a quick regex refresher:
- Pattern Matching: Regex uses patterns to match specific strings of text. For example, the pattern
image\.(jpg|png|gif)$would match any image file ending in .jpg, .png, or .gif. - Wildcards: You can use wildcards like
*(matches any sequence of characters) and?(matches any single character) to create more flexible patterns. - Grouping: Parentheses
()can be used to group parts of a pattern together.
How to Use Regex in X-Robots-Tags:
- In Meta Robots Tag: HTML
<meta name="robots" content="noindex: /images/*.jpg$">This would prevent all JPG images in the “/images/” directory from being indexed. - In HTTP Header:
X-Robots-Tag: noindex: /blog/archives/*This would prevent all pages within the “/blog/archives/” directory from being indexed.
Advanced Use Cases:
- Selective Indexing: You could use regex to index only specific types of pages or files, while excluding others.
- Fine-Grained Control: You could create rules that apply only to certain search engines or user agents.
- Dynamic Content: Regex can be used to manage indexing of pages that change frequently or are generated dynamically.
Remember: Regex is powerful, but it can also be tricky. A small mistake in your pattern can have unintended consequences. Always test your regex thoroughly before implementing it on your live site.
Additional Tip:
X-Robots-Tag: googlebot: noindex: This directive specifically targets Googlebot, allowing you to give different instructions to other search engine crawlers.
By mastering regex, you can wield the X-Robots-Tag like a precision tool, tailoring your instructions to fit the unique needs of your website.
Common Mistakes (and How to Avoid Them!)
Even with the best intentions, it’s easy to trip up when using X-Robots-Tags. Here are some common mistakes to watch out for:
- Conflicting Instructions: Imagine telling a search engine bot to both index a page AND not index it. They’ll be scratching their digital heads! Make sure you don’t have conflicting directives within the same X-Robots-Tag or between X-Robots-Tags and meta robots tags.
- Blocking Access While Telling Bots to “Noindex”: If you’re using your robots.txt file to block search engines from crawling a page, they won’t even see your “noindex” directive! For a page to be removed from the index, search engine bots need to be able to access it and see the instructions.
- Overusing “Noindex”: It might be tempting to slap a “noindex” on every page you’re not sure about, but be careful! You could accidentally hide important content that you actually want to show up in search results.
- Ignoring Caching: Even if you tell search engines not to index a page, they might still have a cached version of it. If you really want a page to disappear, consider using the
noarchivedirective as well. - Incorrect Syntax: Double-check your X-Robots-Tag for typos or missing commas. Even small errors can prevent the tag from working properly.
Bonus Tip: X-Robots-Tags aren’t foolproof! Determined individuals can still find “hidden” pages if they know where to look. If you have truly confidential information, consider additional security measures.
Troubleshooting Common X-Robots-Tag Issues:
Even with the best intentions, things don’t always go smoothly. Here are some common issues you might encounter with X-Robots-Tags, along with their solutions:
1. Pages Not Being Removed from Search Results:
- Possible Cause: Search engines cache pages, so even if you’ve set a
noindexdirective, the cached version might still appear for a while. - Solution:
- Use the
noarchivedirective to prevent caching. - Submit a removal request through Google Search Console.
- Be patient, as it can take time for search engines to update their index.
- Use the
2. X-Robots-Tag Not Being Recognized:
- Possible Cause: The tag might be implemented incorrectly, or there might be a conflicting directive elsewhere (e.g., in the robots.txt file).
- Solution:
- Double-check the syntax and placement of the tag.
- Look for conflicting directives in other parts of your site.
- Use online tools or Google Search Console to verify if the tag is being read correctly.
3. Unintended Pages Being Blocked:
- Possible Cause: A typo in the X-Robots-Tag or an overly broad regex pattern can accidentally block pages you didn’t intend to.
- Solution:
- Carefully review your tags and regex patterns.
- Test the implementation on a staging environment before applying it to your live site.
4. X-Robots-Tag Not Working for All Bots:
- Possible Cause: Not all bots respect all directives. Some bots might ignore X-Robots-Tags altogether.
- Solution:
- Research the specific bot you’re trying to control to see which directives it supports.
- Consider using additional methods, such as IP blocking or password protection, for sensitive content.
5. Delayed Updates in Search Results:
- Possible Cause: Search engines don’t crawl and index pages instantly. Changes you make with X-Robots-Tags might take some time to reflect in search results.
- Solution:
- Be patient. Monitor your search results and use tools like Google Search Console to track progress.
- You can request faster indexing through Google Search Console, but it’s not guaranteed.
Remember, troubleshooting is often a process of trial and error. Don’t be afraid to experiment and test different approaches to find what works best for your situation.
Wrapping Up: Your Website, Your Rules
The X-Robots-Tag might seem like a small piece of code, but it gives you a surprising amount of power over how search engines interact with your website. It’s your way of saying, “Hey bots, pay attention to my instructions!”
Whether you want to keep certain pages private, fine-tune your SEO strategy, or protect your images from being misused, the X-Robots-Tag is a valuable tool in your arsenal.
Key Takeaways:
- X-Robots-Tags are instructions for search engines, embedded in the HTTP headers of web pages or files.
- They can be used to control whether a page is indexed, followed, archived, or displayed in search results.
- There are different directives you can use, and you can even combine them.
- Choose the implementation method that suits your technical skills and website setup.
- Be aware of common mistakes and use X-Robots-Tags responsibly.
By mastering the X-Robots-Tag, you’re not just managing a website – you’re shaping how the world discovers your content. So go ahead, give those search engine bots a friendly nudge in the right direction!